Beispiele und Anwendungen
In dieser Lektion werden wir einige Beispiele für variationelle Algorithmen und deren Anwendung untersuchen:
- Wie man einen benutzerdefinierten variationellen Algorithmus schreibt
- Wie man einen variationellen Algorithmus anwendet, um minimale Eigenwerte zu finden
- Wie man variationelle Algorithmen nutzt, um Anwendungsfälle zu lösen
Beachte, dass das Qiskit-Patterns-Framework auf alle hier vorgestellten Probleme angewendet werden kann. Um Wiederholungen zu vermeiden, werden wir die Framework-Schritte jedoch nur in einem Beispielfall explizit aufrufen, der auf realer Hardware ausgeführt wird.
Problemdefinitionen
Stell dir vor, wir möchten einen variationellen Algorithmus verwenden, um den Eigenwert der folgenden Observable zu finden:
Diese Observable hat die folgenden Eigenwerte:
Und Eigenzustände:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
Benutzerdefinierter VQE
Wir werden zunächst untersuchen, wie man eine VQE-Instanz manuell konstruiert, um den niedrigsten Eigenwert für zu finden. Dies wird eine Vielzahl von Techniken einbeziehen, die wir in diesem Kurs behandelt haben.
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
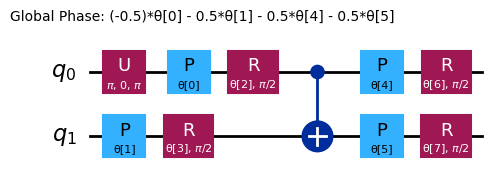
Wir beginnen mit dem Debuggen auf lokalen Simulatoren.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Jetzt legen wir einen anfänglichen Parametersatz fest:
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
Wir können diese Kostenfunktion minimieren, um optimale Parameter zu berechnen.
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
Da dieses Spielzeugproblem nur zwei Qubits verwendet, können wir dies mit NumPys linearem Algebra-Eigenwertlöser überprüfen.
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
Wie du sehen kannst, liegt das Ergebnis extrem nahe am Idealwert.
Experimentieren zur Verbesserung von Geschwindigkeit und Genauigkeit
Referenzzustand hinzufügen
Im vorherigen Beispiel haben wir keinen Referenzoperator verwendet. Überlegen wir nun, wie der ideale Eigenzustand erhalten werden kann. Betrachte die folgende Schaltung.
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

Wir können schnell überprüfen, dass diese Schaltung uns den gewünschten Zustand liefert.
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
Nachdem wir gesehen haben, wie eine Schaltung aussieht, die den Lösungszustand vorbereitet, erscheint es vernünftig, ein Hadamard-Gate als Referenzschaltung zu verwenden, sodass der vollständige Ansatz wie folgt wird:
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
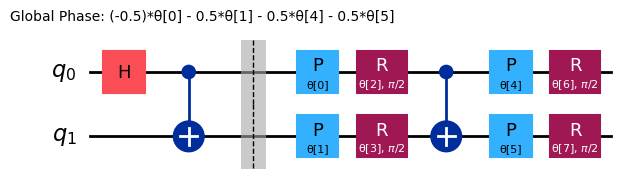
Für diese neue Schaltung könnte die ideale Lösung mit allen auf gesetzten Parametern erreicht werden, was bestätigt, dass die Wahl der Referenzschaltung vernünftig ist.
Vergleichen wir nun die Anzahl der Kostenfunktionsauswertungen, Optimierer-Iterationen und die benötigte Zeit mit denen des vorherigen Versuchs.
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
Wir verwenden unsere optimalen Parameter, um den minimalen Eigenwert zu berechnen:
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
Abhängig von deinem spezifischen System kann dies bei diesem sehr kleinen Beispiel zu einer Verbesserung der Geschwindigkeit oder Genauigkeit führen oder auch nicht. Der Punkt ist, dass das Beginnen mit physikalisch motivierten Referenzzuständen bei der Verbesserung von Geschwindigkeit und Genauigkeit mit zunehmender Problemgröße immer wichtiger wird.
Anfangspunkt ändern
Nachdem wir die Auswirkung des Hinzufügens des Referenzzustands gesehen haben, werden wir uns ansehen, was passiert, wenn wir verschiedene Anfangspunkte wählen. Insbesondere werden wir und verwenden.
Denke daran, dass, wie bei der Einführung des Referenzzustands besprochen, die ideale Lösung gefunden würde, wenn alle Parameter sind, sodass der erste Anfangspunkt weniger Auswertungen ergeben sollte.
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
Anfangspunkt auf anpassen:
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
Durch das Experimentieren mit verschiedenen Anfangspunkten kannst du möglicherweise eine schnellere Konvergenz mit weniger Funktionsauswertungen erreichen.
Experimentieren mit verschiedenen Optimierern
Wir können den Optimierer über das method-Argument von SciPys minimize anpassen, weitere Optionen findest du hier. Ursprünglich haben wir einen eingeschränkten Minimierer (COBYLA) verwendet. In diesem Beispiel werden wir stattdessen einen uneingeschränkten Minimierer (BFGS) ausprobieren.
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
VQD-Beispiel
Hier implementieren wir das Qiskit-Patterns-Framework explizit.
Schritt 1: Klassische Eingaben auf ein Quantenproblem abbilden
Anstatt nur den niedrigsten Eigenwert unserer Observablen zu suchen, werden wir jetzt alle suchen (wobei ).
Denke daran, dass die Kostenfunktionen von VQD wie folgt lauten:
Dies ist besonders wichtig, da ein Vektor (in diesem Fall ) als Argument übergeben werden muss, wenn wir das VQD-Objekt definieren.
Außerdem werden in Qiskits Implementierung von VQD, anstatt die im vorherigen Notebook beschriebenen effektiven Observablen zu betrachten, die Fidelitäten direkt über den ComputeUncompute-Algorithmus berechnet, der ein Sampler-Primitiv nutzt, um die Wahrscheinlichkeit zu sampeln, für die Schaltung
zu erhalten. Dies funktioniert genau deshalb, weil diese Wahrscheinlichkeit
ist.
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
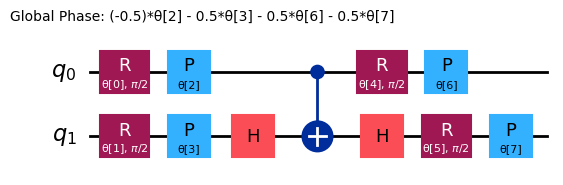
Beginnen wir mit der Untersuchung der folgenden Observable:
Diese Observable hat die folgenden Eigenwerte:
Und Eigenzustände:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
Wir werden die folgende Funktion verwenden, um die Überlappungsstrafe zu berechnen. Beachte, dass dies immer noch Teil der Abbildung des Problems auf Quantenschaltungen ist. Wie in der vorherigen Lektion besprochen, berechnet diese Funktion jedoch die Überlappung zwischen einer aktuellen variationellen Schaltung und der optimierten Schaltung aus einem vorherigen, energieärmeren/kostenärmeren Zustand. Die neue Schaltung, die erzeugt wird, muss ebenfalls transpiliert werden, um auf realer Hardware zu laufen. Wir haben diese Funktion zuvor gesehen, verwendet auf einem Simulator. Hier müssen wir bereits die Transpilierung und zugehörige Optimierung für die Verwendung eines realen Backends berücksichtigen, daher die Zeilen rund um if realbackend == 1. Dies vermischt sich etwas mit Schritt 2, aber wir werden Schritt 2 später explizit aufrufen.
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
Jetzt fügen wir die Kostenfunktion von VQD hinzu. Beachte, dass wir im Vergleich zur vorherigen Lektion jetzt zwei zusätzliche Argumente (realbackend und backend) haben, die uns bei der Transpilierung helfen, wenn wir reale Backends verwenden.
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
Wieder werden wir Simulatoren zum Debuggen verwenden und dann zu realer Hardware übergehen.
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
Hier führen wir die Anzahl der Zustände ein, die wir berechnen möchten, die Strafterme und einen Satz von Anfangsparametern x0.
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
Wir werden den Algorithmus nun mit Simulatoren testen:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
Diese Ergebnisse liegen recht nahe an den erwarteten Werten, abgesehen von Approximationsfehlern und globaler Phase. Wir könnten die Toleranz des klassischen Optimierers und/oder die Strafterme für die Zustandsvektor-Überlappung anpassen, um genauere Werte zu erhalten.
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
Betas ändern
Wie in der vorherigen Lektion erwähnt, sollten die Werte von größer sein als die Differenz zwischen den Eigenwerten. Sehen wir uns an, was passiert, wenn sie diese Bedingung für nicht erfüllen.
mit Eigenwerten
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
Diesmal gibt der Optimierer denselben Zustand als vorgeschlagene Lösung für alle Eigenzustände zurück: was offensichtlich falsch ist. Dies geschieht, weil die Betas zu klein waren, um den minimalen Eigenzustand in den aufeinanderfolgenden Kostenfunktionen zu bestrafen. Daher wurde er nicht aus dem effektiven Suchraum in späteren Iterationen des Algorithmus ausgeschlossen und immer als die bestmögliche Lösung gewählt.
Wir empfehlen, mit den Werten von zu experimentieren und sicherzustellen, dass sie größer als die Differenz zwischen den Eigenwerten sind.
Schritt 2: Problem für die Quantenausführung optimieren
Um dies auf realer Hardware auszuführen, müssen wir die Quantenschaltungen für unseren gewählten Quantencomputer optimieren. Für unsere Zwecke hier werden wir einfach das am wenigsten ausgelastete Backend verwenden.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
Wir werden unsere Schaltung mit einem voreingestellten Pass-Manager und Optimierungsstufe 3 transpilieren.
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
Schritt 3: Mit Qiskit-Primitiven ausführen
Achte darauf, unsere Betas auf ausreichend hohe Werte zurückzusetzen, dann können wir unsere Berechnung auf realer Quantenhardware ausführen.
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Schritt 4: Nachbearbeitung, Ergebnis im klassischen Format zurückgeben
Unsere Ausgabe ist strukturell ähnlich zu dem, was in vorherigen Lektionen und Beispielen besprochen wurde. Aber es gibt etwas Problematisches in den obigen Ergebnissen, woraus wir eine warnende Botschaft für den Kontext angeregter Zustände ableiten können. Um die in diesem Lernbeispiel verwendete Rechenzeit zu begrenzen, haben wir eine maximale Anzahl von Iterationen für den klassischen Optimierer festgelegt, die möglicherweise zu niedrig war: 200 Iterationen. Eine vorherige Berechnung oben, auf einem Simulator, konvergierte nicht in 200 Iterationen. Hier konvergierte unsere... aber mit welcher Toleranz? Wir haben keine Toleranz für COBYLA angegeben, ab der es sich als „konvergiert" betrachtet. Ein Blick auf den Funktionswert und der Vergleich mit vorherigen Durchläufen zeigt uns, dass COBYLA nicht nahe daran war, mit der von uns benötigten Präzision zu konvergieren.
Es gibt ein weiteres Problem: Die Energie des ersten angeregten Zustands scheint niedriger zu sein als die Energie des Grundzustands! Versuche zu erklären, wie das passieren konnte. Hinweis: Es hängt mit dem gerade angesprochenen Konvergenzpunkt zusammen. Dieses Verhalten wird weiter unten im Detail erklärt, nachdem VQD auf das H2-Molekül angewendet wurde.
Quantenchemie: Grundzustands- und angeregte-Zustands-Energielöser
Unser Ziel ist es, den Erwartungswert der Observable zu minimieren, die die Energie darstellt (Hamiltonian ):
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
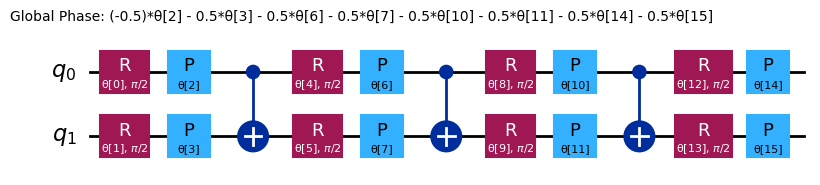
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
Jetzt setzen wir einen anfänglichen Satz von Parametern:
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
Wir können diese Kostenfunktion minimieren, um optimale Parameter zu berechnen, und wir können unseren Code zunächst mit einem lokalen Simulator überprüfen.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
Der Minimalwert der Kostenfunktion (-1.857...) ist die Grundzustandsenergie des H2-Moleküls in Einheiten von Hartree.
Angeregte Zustände
Wir können auch VQD nutzen, um insgesamt Zustände zu lösen (den Grundzustand und den ersten angeregten Zustand).
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
Wir fügen unsere Überlappungsberechnung hinzu:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
Reale Hardware und eine abschließende Warnung
Um dies auf realer Hardware auszuführen, müssen wir die Quantenschaltungen für unseren gewählten Quantencomputer optimieren. Für unsere Zwecke hier werden wir einfach das am wenigsten ausgelastete Backend verwenden.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
Wir werden einen voreingestellten Pass-Manager für die Transpilierung verwenden und unsere Schaltung mit Optimierungsstufe 3 maximal optimieren.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
Da VQD hochgradig iterativ ist, werden wir alle Schritte innerhalb einer Runtime-Session ausführen, sodass unsere Jobs nur am Anfang in die Warteschlange gestellt werden und nicht zwischen jeder Parameteraktualisierung. An der Syntax für die Kostenfunktion oder den Estimator ändert sich nichts anderes.
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Die erhaltene Grundzustandsenergie (-1,83 Hartree) liegt nicht allzu weit vom korrekten Wert (-1,85 Hartree) entfernt. Die Energie des angeregten Zustands weicht jedoch ziemlich stark ab. Dies ähnelt dem fehlerhaften Verhalten, das wir zuvor in dieser Lektion gesehen haben. Die gemeldete Energie für den angeregten Zustand ist nahezu gleich der des Grundzustands. Im vorherigen Fall sahen wir sogar eine Energie des angeregten Zustands, die niedriger war als die gemeldete Grundzustandsenergie.
Es ist für eine variationelle Berechnung nicht möglich, eine Energie zu liefern, die niedriger als die wahre Grundzustandsenergie ist. Im früheren Fall war die von uns erhaltene Grundzustandsenergie nicht sehr nahe am wahren Grundzustand. Da wir in diesem Fall die wahre Grundzustandsenergie nicht erhalten haben, gibt es keinen Widerspruch. Im vorliegenden Fall lag die Grundzustandsenergie recht nahe am korrekten Wert, und dennoch scheint die Energie des angeregten Zustands merkwürdig nahe an diesem Wert zu liegen.
Um besser zu verstehen, wie das passiert ist, erinnere dich daran, dass wir einen angeregten Zustand finden, indem wir verlangen, dass der variationelle Zustand orthogonal zum Grundzustand ist (unter Verwendung der Überlappungsschaltungen und Strafterme). Wenn wir es nicht schaffen, eine genaue Grundzustandsenergie zu erhalten (oder um einige Prozent daneben liegen), dann erhalten wir auch keinen genauen Grundzustandsvektor! Wenn wir also verlangen, dass der angeregte Zustand orthogonal zum ersten gefundenen Zustand ist, haben wir nicht die Orthogonalität zum wahren Grundzustand erzwungen, sondern zu einer Approximation davon (manchmal einer schlechten Approximation). Daher war der angeregte Zustand nicht gezwungen, orthogonal zum wahren Grundzustand zu sein, und unsere Energieschätzungen für die angeregten Zustände lagen tatsächlich recht nahe an der Grundzustandsenergie.
Dies wird immer ein Problem bei VQD sein. Aber im Prinzip kann dies korrigiert werden, indem die maximale Anzahl von Iterationen für den klassischen Optimierer erhöht wird, eine niedrigere Toleranz für den klassischen Optimierer festgelegt wird und möglicherweise auch ein anderer Ansatz ausprobiert wird, wenn wir den wahren Grundzustand gewohnheitsmäßig verfehlen. Wie wir gesehen haben, muss man möglicherweise auch die Überlappungsstrafterme (Betas) anpassen. Aber das ist wirklich ein separates Problem. Kein Strafterm für die Überlappung wird dich vom wahren Grundzustand fernhalten, wenn du keine sehr gute Schätzung des wahren Grundzustands für die Überlappungsschaltung gefunden hast.
Optimierung: max-cut
Das Maximum-Cut-Problem (max-cut) ist ein kombinatorisches Optimierungsproblem, bei dem die Knoten eines Graphen in zwei disjunkte Mengen aufgeteilt werden, sodass die Anzahl der Kanten zwischen den beiden Mengen maximiert wird. Formaler ausgedrückt: Gegeben sei ein ungerichteter Graph , wobei die Menge der Knoten und die Menge der Kanten ist, fordert das max-cut-Problem, die Knoten in zwei disjunkte Teilmengen und zu partitionieren, sodass die Anzahl der Kanten mit einem Endpunkt in und dem anderen in maximiert wird.
Wir können max-cut auf verschiedene Probleme anwenden, wie z.B. Clustering, Netzwerkdesign und Phasenübergänge. Wir beginnen mit der Erstellung eines Problemgraphen:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

Dieses Problem kann als binäres Optimierungsproblem ausgedrückt werden. Für jeden Knoten , wobei die Anzahl der Knoten des Graphen ist (in diesem Fall ), betrachten wir die binäre Variable . Diese Variable hat den Wert , wenn Knoten in einer der Gruppen ist, die wir als bezeichnen, und , wenn er in der anderen Gruppe ist, die wir als bezeichnen. Wir bezeichnen auch (Element der Adjazenzmatrix ) als das Gewicht der Kante, die von Knoten zu Knoten geht. Da der Graph ungerichtet ist, gilt . Dann können wir unser Problem als Maximierung der folgenden Kostenfunktion formulieren:
Um dieses Problem mit einem Quantencomputer zu lösen, werden wir die Kostenfunktion als Erwartungswert einer Observable ausdrücken. Die Observablen, die Qiskit nativ akzeptiert, bestehen jedoch aus Pauli-Operatoren, die Eigenwerte und anstelle von und haben. Deshalb werden wir die folgende Variablensubstitution vornehmen:
Wobei . Wir können die Adjazenzmatrix verwenden, um bequem auf die Gewichte aller Kanten zuzugreifen. Dies wird verwendet, um unsere Kostenfunktion zu erhalten:
Dies impliziert:
Die neue Kostenfunktion, die wir maximieren wollen, ist also:
Darüber hinaus ist die natürliche Tendenz eines Quantencomputers, Minima (normalerweise die niedrigste Energie) zu finden statt Maxima, daher werden wir anstatt zu maximieren, Folgendes minimieren:
Jetzt, da wir eine zu minimierende Kostenfunktion haben, deren Variablen die Werte und annehmen können, können wir die folgende Analogie zum Pauli- herstellen:
Mit anderen Worten, die Variable wird einem -Gate gleichgesetzt, das auf Qubit wirkt. Darüber hinaus:
Dann ist die Observable, die wir betrachten werden:
zu der wir den unabhängigen Term nachträglich hinzufügen müssen:
Der Operator ist eine Linearkombination von Termen mit Z-Operatoren auf durch eine Kante verbundenen Knoten (denke daran, dass das 0. Qubit ganz rechts steht): . Sobald der Operator konstruiert ist, kann der Ansatz für den QAOA-Algorithmus einfach mit der QAOAAnsatz-Schaltung aus der Qiskit-Schaltungsbibliothek erstellt werden.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Jetzt setzen wir einen anfänglichen Satz zufälliger Parameter:
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
Jeder klassische Optimierer kann verwendet werden, um die Kostenfunktion zu minimieren. Auf einem realen Quantensystem funktioniert ein Optimierer, der für nicht-glatte Kostenfunktionslandschaften konzipiert ist, normalerweise besser. Hier verwenden wir die COBYLA-Routine von SciPy über die minimize-Funktion.
Da wir iterativ viele Aufrufe an Runtime ausführen, nutzen wir eine Session, um alle Aufrufe innerhalb eines einzelnen Blocks auszuführen. Darüber hinaus ist bei QAOA die Lösung in der Ausgabeverteilung der Ansatz-Schaltung kodiert, die mit den optimalen Parametern aus der Minimierung gebunden ist. Daher benötigen wir ein Sampler-Primitiv und werden es mit derselben Session instanziieren. Und führen unsere Minimierungsroutine aus:
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
Der Lösungsvektor der Parameterwinkel (x), eingesetzt in die Ansatz-Schaltung, liefert die Graphpartitionierung, die wir gesucht haben.
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

Zusammenfassung
In dieser Lektion hast du gelernt:
- Wie man einen benutzerdefinierten variationellen Algorithmus schreibt
- Wie man einen variationellen Algorithmus anwendet, um minimale Eigenwerte zu finden
- Wie man variationelle Algorithmen nutzt, um Anwendungsfälle zu lösen
Fahre mit der letzten Lektion fort, um deine Bewertung abzulegen und dein Abzeichen zu verdienen!