Datenkodierung
Einführung und Notation
Um einen Quantenalgorithmus zu verwenden, müssen klassische Daten irgendwie in einen Quantenschaltkreis überführt werden. Dies wird üblicherweise als Daten-Kodierung bezeichnet, manchmal aber auch als Daten-Laden. Erinnere dich aus früheren Lektionen an das Konzept des Feature-Mappings – eine Abbildung von Datenmerkmalen aus einem Raum in einen anderen. Das bloße Übertragen klassischer Daten auf einen Quantencomputer ist eine Art Abbildung und könnte als Feature-Mapping bezeichnet werden. In der Praxis beinhalten die in Qiskit eingebauten Feature-Mappings (wie z_feature_map und zz_feature_map) typischerweise Rotationsschichten und Verschränkungsschichten, die den Zustand auf viele Dimensionen im Hilbertraum ausdehnen. Dieser Kodierungsprozess ist ein wesentlicher Bestandteil von Quantenmaschinellen-Lern-Algorithmen und beeinflusst direkt deren Berechnungsmöglichkeiten.
Einige der unten vorgestellten Kodierungstechniken lassen sich effizient klassisch simulieren; das ist besonders leicht bei Kodierungsmethoden zu erkennen, die Produktzustände erzeugen (d. h. keine Qubits verschränken). Denke außerdem daran, dass Quanten-Nützlichkeit am wahrscheinlichsten dort zu finden ist, wo die quantenartige Komplexität des Datensatzes gut zur Kodierungsmethode passt. Es ist daher sehr wahrscheinlich, dass du eigene Kodierungsschaltkreise entwickeln wirst. Hier zeigen wir eine breite Auswahl möglicher Kodierungsstrategien, damit du sie vergleichen und Unterschiede erkennen kannst, und siehst, was möglich ist. Es gibt einige sehr allgemeine Aussagen über die Nützlichkeit von Kodierungstechniken. So ist es beispielsweise viel wahrscheinlicher, dass efficient_su2 (siehe unten) mit einem vollständigen Verschränkungsschema Quantenmerkmale von Daten erfasst als Methoden, die Produktzustände liefern (wie z_feature_map). Das bedeutet jedoch nicht, dass efficient_su2 ausreichend oder ausreichend gut auf deinen Datensatz abgestimmt ist, um eine Quantenbeschleunigung zu erzielen. Das erfordert eine sorgfältige Betrachtung der Struktur der zu modellierenden oder klassifizierenden Daten. Es gibt auch einen Abwägungsprozess bezüglich der Schaltkreistiefe, da viele Feature-Maps, die die Qubits in einem Schaltkreis vollständig verschränken, sehr tiefe Schaltkreise erzeugen – zu tief, um auf heutigen Quantencomputern brauchbare Ergebnisse zu erhalten.
Notation
Ein Datensatz ist eine Menge von Datenvektoren: , wobei jeder Vektor -dimensional ist, d. h. . Dies lässt sich auf komplexe Datenmerkmale erweitern. In dieser Lektion verwenden wir gelegentlich diese Notationen für die vollständige Menge und ihre spezifischen Elemente wie . Meistens werden wir uns jedoch auf das Laden eines einzelnen Vektors aus unserem Datensatz beziehen und oft einfach von einem einzelnen Vektor aus Merkmalen als sprechen.
Außerdem ist es üblich, das Symbol für das Feature-Mapping des Datenvektors zu verwenden. Im Quantencomputing ist es insbesondere üblich, Abbildungen mit zu bezeichnen – eine Notation, die den unitären Charakter dieser Operationen betont. Man könnte korrekterweise dasselbe Symbol für beides verwenden; beides sind Feature-Mappings. Im gesamten Kurs verwenden wir:
- , wenn wir allgemein über Feature-Mappings im Maschinellen Lernen sprechen, und
- , wenn wir über Schaltkreisimplementierungen von Feature-Mappings sprechen.
Normalisierung und Informationsverlust
Im klassischen Maschinellen Lernen werden Trainings-Datenmerkmale häufig „normalisiert" oder umskaliert, was oft die Modellleistung verbessert. Eine gängige Methode ist die Min-Max-Normalisierung oder Standardisierung. Bei der Min-Max-Normalisierung werden Merkmalsspalten der Datenmatrix (z. B. Merkmal ) normalisiert:
wobei min und max das Minimum bzw. Maximum von Merkmal über die Datenvektoren im Datensatz bezeichnen. Alle Merkmalswerte liegen dann im Einheitsintervall: für alle , .
Normalisierung ist auch ein fundamentales Konzept in der Quantenmechanik und im Quantencomputing, unterscheidet sich jedoch leicht von der Min-Max-Normalisierung. Normalisierung in der Quantenmechanik erfordert, dass die Länge (im Kontext des Quantencomputings die 2-Norm) eines Zustandsvektors gleich eins ist: , um sicherzustellen, dass die Messprobabilitäten sich zu 1 addieren. Der Zustand wird durch Division durch die 2-Norm normalisiert; das heißt, durch Umskalierung
Im Quantencomputing und in der Quantenmechanik ist dies keine von Menschen auf die Daten aufgezwungene Normalisierung, sondern eine fundamentale Eigenschaft von Quantenzuständen. Je nach deinem Kodierungsschema kann diese Bedingung beeinflussen, wie deine Daten umskaliert werden. Bei der Amplitudenkodierung (siehe unten) beispielsweise wird der Datenvektor normalisiert , wie es die Quantenmechanik erfordert, und das beeinflusst die Skalierung der kodierten Daten. Bei der Phasenkodierung wird empfohlen, Daten auf umzuskalieren, um Informationsverluste durch den Modulo--Effekt bei der Kodierung in einen Qubit-Phasenwinkel zu vermeiden[1,2].
Kodierungsmethoden
In den nächsten Abschnitten beziehen wir uns auf einen kleinen klassischen Beispieldatensatz , bestehend aus Datenvektoren mit jeweils Merkmalen:
In der oben eingeführten Notation könnte man beispielsweise sagen, das Merkmal des Datenvektors in unserem Datensatz ist .
Basiskodierung
Basiskodierung kodiert einen klassischen -Bit-String in einen Rechenbasisszustand eines -Qubit-Systems. Nehmen wir zum Beispiel . Dies lässt sich als -Bit-String darstellen und durch ein -Qubit-System als Quantenzustand . Allgemeiner gilt für einen -Bit-String: – der entsprechende -Qubit-Zustand ist mit für . Beachte, dass dies nur für ein einzelnes Merkmal gilt.
Basiskodierung im Quantencomputing repräsentiert jedes klassische Bit als separates Qubit und bildet die binäre Darstellung von Daten direkt auf Quantenzustände in der Rechenbasis ab. Wenn mehrere Merkmale kodiert werden müssen, wird jedes Merkmal zunächst in seine binäre Form umgewandelt und dann einer eigenen Qubit-Gruppe zugewiesen – eine Gruppe pro Merkmal – wobei jedes Qubit ein Bit in der Binärdarstellung dieses Merkmals widerspiegelt.
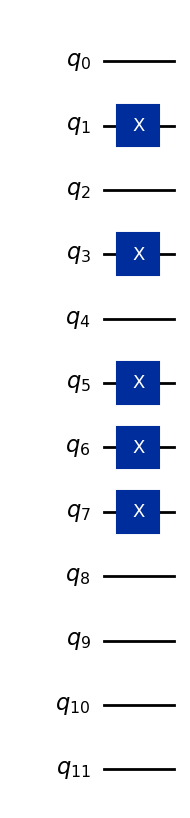
Als Beispiel kodieren wir den Vektor (5, 7, 0).
Angenommen, alle Merkmale werden in vier Bits gespeichert (mehr als nötig, aber genug, um jede einstellige ganze Zahl in Basis 10 darzustellen):
5 → binär 0101
7 → binär 0111
0 → binär 0000
Diese Bit-Strings werden drei Gruppen von je vier Qubits zugewiesen, sodass der gesamte 12-Qubit-Basiszustand lautet:
Dabei repräsentieren die ersten vier Qubits das erste Merkmal, die nächsten vier Qubits das zweite Merkmal und die letzten vier Qubits das dritte Merkmal. Der folgende Code konvertiert den Datenvektor (5,7,0) in einen Quantenzustand und ist so verallgemeinert, dass er dies auch für andere einstellige Merkmale tut.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Überprüfe dein Verständnis
Schreibe Code, um den ersten Vektor in unserem Beispieldatensatz zu kodieren:
mithilfe von Basiskodierung.
Antwort
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Amplitudenkodierung
Amplitudenkodierung kodiert Daten in die Amplituden eines Quantenzustands. Sie repräsentiert einen normalisierten klassischen -dimensionalen Datenvektor als die Amplituden eines -Qubit-Quantenzustands :
wobei dieselbe Dimension der Datenvektoren wie zuvor ist, das -te Element von und der -te Rechenbasiszustand. Hier ist eine Normalisierungskonstante, die aus den zu kodierenden Daten bestimmt wird. Dies ist die durch die Quantenmechanik aufgezwungene Normalisierungsbedingung:
Im Allgemeinen ist dies eine andere Bedingung als die Min-Max-Normalisierung, die für jedes Merkmal über alle Datenvektoren verwendet wird. Wie genau damit umgegangen wird, hängt von deinem Problem ab. An der quantenmechanischen Normalisierungsbedingung oben führt jedoch kein Weg vorbei.
Bei der Amplitudenkodierung wird jedes Merkmal eines Datenvektors als Amplitude eines anderen Quantenzustands gespeichert. Da ein System aus Qubits Amplituden bereitstellt, erfordert die Amplitudenkodierung von Merkmalen Qubits.
Als Beispiel kodieren wir den ersten Vektor in unserem Beispieldatensatz , , mithilfe von Amplitudenkodierung. Durch Normalisierung des resultierenden Vektors erhalten wir:
und der resultierende 2-Qubit-Quantenzustand wäre:
Im obigen Beispiel ist die Anzahl der Merkmale im Vektor keine Potenz von 2. Wenn keine Potenz von 2 ist, wählen wir einfach eine Anzahl von Qubits so, dass gilt, und füllen den Amplitudenvektor mit uninformativen Konstanten auf (hier eine Null).
Wie bei der Basiskodierung können wir in Qiskit die initialize-Funktion verwenden, um den Zustand vorzubereiten, sobald wir berechnet haben, welcher Zustand unseren Datensatz kodieren wird:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Ein Vorteil der Amplitudenkodierung ist der bereits erwähnte Bedarf von nur Qubits zur Kodierung. Allerdings müssen nachfolgende Algorithmen auf den Amplituden eines Quantenzustands operieren, und Methoden zur Vorbereitung und Messung der Quantenzustände neigen dazu, nicht effizient zu sein.
Überprüfe dein Verständnis
Schreibe den normalisierten Zustand für die Kodierung des folgenden Vektors (bestehend aus zwei Vektoren unseres Beispieldatensatzes) auf:
mithilfe von Amplitudenkodierung.
Antwort
Um 6 Zahlen zu kodieren, benötigen wir mindestens 6 verfügbare Zustände, auf deren Amplituden wir kodieren können. Dafür sind 3 Qubits erforderlich. Mit einem unbekannten Normalisierungsfaktor lässt sich dies schreiben als:
Beachte, dass
Somit gilt schließlich:
Für denselben Datenvektor schreibe Code, um einen Schaltkreis zu erstellen, der diese Datenmerkmale mithilfe von Amplitudenkodierung lädt.
Antwort
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Möglicherweise musst du mit sehr großen Datenvektoren umgehen. Betrachte den Vektor
Schreibe Code, um die Normalisierung zu automatisieren und einen Quantenschaltkreis für die Amplitudenkodierung zu erzeugen.
Antwort
Es gibt viele mögliche Antworten. Hier ist Code, der einige Zwischenschritte ausgibt:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Siehst du Vorteile der Amplitudenkodierung gegenüber der Basiskodierung? Falls ja, erkläre sie.
Antwort
Es kann mehrere Antworten geben. Eine Antwort ist, dass die Amplitudenkodierung – aufgrund der festen Reihenfolge der Basiszustände – die Ordnung der kodierten Zahlen erhält. Sie wird oft auch dichter kodiert.
Ein Vorteil der Amplitudenkodierung ist, dass für einen -dimensionalen (-merkmaligen) Datenvektor nur Qubits benötigt werden. Die Amplitudenkodierung ist jedoch generell ein ineffizientes Verfahren, das eine beliebige Zustandspräparation erfordert, die exponentiell in der Anzahl der CNOT-Gates ist. Anders ausgedrückt: Die Zustandspräparation hat eine polynomielle Laufzeitkomplexität von in der Anzahl der Dimensionen, wobei und die Anzahl der Qubits ist. Amplitudenkodierung „bietet eine exponentielle Einsparung im Speicherbedarf auf Kosten einer exponentiellen Erhöhung der Zeit"[3]; jedoch sind Laufzeitsteigerungen auf in bestimmten Fällen erreichbar[4]. Für eine durchgehende Quantenbeschleunigung muss die Laufzeitkomplexität des Datenladens berücksichtigt werden.
Winkelkodierung
Winkelkodierung ist in vielen QML-Modellen, die Pauli-Feature-Maps verwenden – wie Quanten-Support-Vektor-Maschinen (QSVMs) und variationelle Quantenschaltkreise (VQCs) – von Interesse. Winkelkodierung ist eng verwandt mit Phasenkodierung und dichter Winkelkodierung, die weiter unten vorgestellt werden. Hier verwenden wir „Winkelkodierung" für eine Rotation in , also eine Rotation weg von der -Achse, die beispielsweise durch ein - oder ein -Gate erreicht wird[1,3]. Grundsätzlich kann man Daten in jeder Rotation oder Kombination von Rotationen kodieren. Aber ist in der Literatur weit verbreitet, weshalb wir es hier besonders betonen.
Wenn es auf ein einzelnes Qubit angewendet wird, verleiht die Winkelkodierung eine Y-Achsen-Rotation proportional zum Datenwert. Betrachte die Kodierung eines einzelnen (-ten) Merkmals aus dem -ten Datenvektor eines Datensatzes, :
Alternativ kann die Winkelkodierung mit -Gates durchgeführt werden, obwohl der kodierte Zustand dann im Vergleich zu eine komplexe relative Phase hätte.
Die Winkelkodierung unterscheidet sich von den beiden zuvor besprochenen Methoden in mehrfacher Hinsicht. Bei der Winkelkodierung gilt:
- Jeder Merkmalswert wird auf ein entsprechendes Qubit abgebildet, , wodurch die Qubits in einem Produktzustand verbleiben.
- Es wird jeweils ein numerischer Wert kodiert, nicht eine ganze Menge von Merkmalen eines Datenpunkts.
- Für Datenmerkmale werden Qubits benötigt, wobei gilt. Häufig gilt hier die Gleichheit. In den nächsten Abschnitten werden wir sehen, wie möglich ist.
- Der resultierende Schaltkreis hat eine konstante Tiefe (typischerweise Tiefe 1 vor der Transpilierung).
Der Quantenschaltkreis mit konstanter Tiefe macht ihn besonders geeignet für aktuelle Quantenhardware. Ein weiteres Merkmal der Datenkodierung mit (und insbesondere unserer Wahl, Y-Achsen-Winkelkodierung zu verwenden) ist, dass reell wertige Quantenzustände erzeugt werden, die für bestimmte Anwendungen nützlich sein können. Bei der Y-Achsen-Rotation werden Daten mit einem Y-Achsen-Rotationsgate mit einem reell wertigen Winkel kodiert (Qiskit RYGate). Wie bei der Phasenkodierung (siehe unten) empfehlen wir, Daten so umzuskalieren, dass gilt, um Informationsverluste und andere unerwünschte Effekte zu vermeiden.
Der folgende Qiskit-Code rotiert ein einzelnes Qubit aus einem Anfangszustand , um einen Datenwert zu kodieren.
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Wir definieren eine Funktion, um die Wirkung auf den Zustandsvektor zu visualisieren. Die Details der Funktionsdefinition sind nicht wichtig, aber die Fähigkeit, die Zustandsvektoren und ihre Änderungen zu visualisieren, ist es.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Das war nur ein einzelnes Merkmal eines einzelnen Datenvektors. Wenn Merkmale in die Rotationswinkel von Qubits kodiert werden – beispielsweise für den -ten Datenvektor – sieht der kodierte Produktzustand so aus:
Wir stellen fest, dass dies äquivalent ist zu
Überprüfe dein Verständnis
Kodiere den Datenvektor mit Angle Encoding, wie oben beschrieben.
Antwort
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Wie viele Qubits werden beim oben beschriebenen Angle Encoding benötigt, um 5 Merkmale zu kodieren?
Antwort
5
Phasenkodierung
Phasenkodierung ähnelt dem oben beschriebenen Angle Encoding sehr stark. Der Phasenwinkel eines Qubits ist ein reellwertiger Winkel um die -Achse, gemessen von der -Achse. Die Daten werden mit einer Phasenrotation kodiert: , wobei (siehe Qiskit PhaseGate für weitere Informationen). Es wird empfohlen, die Daten so zu skalieren, dass gilt. Dadurch werden Informationsverluste und andere potenziell unerwünschte Effekte vermieden[1,2].
Ein Qubit wird häufig im Zustand initialisiert, der ein Eigenzustand des Phasenrotationsoperators ist. Das bedeutet, dass der Qubit-Zustand zunächst rotiert werden muss, bevor Phasenkodierung angewendet werden kann. Es ist daher sinnvoll, den Zustand mit einem Hadamard-Gate zu initialisieren: . Phasenkodierung auf einem einzelnen Qubit bedeutet, eine relative Phase proportional zum Datenwert einzuprägen:
Das Phasenkodierungsverfahren bildet jeden Merkmalswert auf die Phase eines entsprechenden Qubits ab: . Insgesamt hat Phasenkodierung eine Circuit-Tiefe von 2, einschließlich der Hadamard-Schicht, was es zu einem effizienten Kodierungsschema macht. Der phasenkodierte Mehr-Qubit-Zustand ( Qubits für Merkmale) ist ein Produktzustand:
Der folgende Qiskit-Code bereitet zunächst den Anfangszustand eines einzelnen Qubits vor, indem es mit einem Hadamard-Gate rotiert wird, und dreht es dann erneut mit einem Phasengatter, um ein Datenmerkmal zu kodieren.
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Wir können die Rotation in mithilfe der zuvor definierten Funktion plot_Nstates visualisieren.
plot_Nstates(states, axis=None, plot_trace_points=True)

Die Bloch-Kugel-Darstellung zeigt die -Achsen-Rotation , wobei . Der hellgrüne Pfeil zeigt den Endzustand.
Phasenkodierung wird in vielen Quanten-Feature-Maps verwendet, insbesondere in der - und -Feature-Map sowie allgemeinen Pauli-Feature-Maps, unter anderem.
Überprüfe dein Verständnis
Wie viele Qubits werden benötigt, um mit der oben beschriebenen Phasenkodierung 8 Merkmale zu speichern?
Antwort
8
Schreibe Code, um den Vektor mit Phasenkodierung zu laden.
Antwort
Es kann viele mögliche Antworten geben. Hier ist ein Beispiel:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Dichtes Winkelkodieren
Dichtes Winkelkodieren (DAE, englisch: Dense Angle Encoding) ist eine Kombination aus Angle Encoding und Phasenkodierung. DAE ermöglicht es, zwei Merkmalswerte in einem einzigen Qubit zu kodieren: einen Winkel mit einer -Achsen-Rotation und den anderen mit einer -Achsen-Rotation: . Zwei Merkmale werden wie folgt kodiert:
Durch die Kodierung von zwei Datenmerkmalen auf einem Qubit wird die Anzahl der erforderlichen Qubits um den Faktor 2 reduziert. Für mehr Merkmale kann der Datenvektor wie folgt kodiert werden:
DAE kann auf beliebige Funktionen der beiden Merkmale verallgemeinert werden, anstatt der hier verwendeten Sinusfunktionen. Dies wird als allgemeine Qubit-Kodierung (general qubit encoding) bezeichnet[7].
Als Beispiel für DAE kodiert und visualisiert der folgende Code die Merkmale und .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Überprüfe dein Verständnis
Wie viele Qubits werden benötigt, um 6 Merkmale mit dichter Kodierung zu kodieren?
Antwort
3
Schreibe Code, um den Vektor mit dichtem Winkelkodieren zu laden.
Antwort
Beachte, dass die Liste mit einer „0" aufgefüllt wurde, um das Problem zu vermeiden, dass ein einzelner Parameter im Kodierungsschema ungenutzt bleibt.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Kodierung mit integrierten Feature-Maps
Kodierung an beliebigen Punkten
Angle Encoding, Phasenkodierung und dichtes Kodieren erzeugen Produktzustände, bei denen ein Merkmal auf jedem Qubit (oder zwei Merkmale pro Qubit) kodiert wird. Das unterscheidet sich von Basis- und Amplitudenkodierung, bei denen verschränkte Zustände genutzt werden. Es gibt keine 1:1-Entsprechung zwischen Datenmerkmal und Qubit. Bei der Amplitudenkodierung könnte beispielsweise ein Merkmal die Amplitude des Zustands und ein anderes die Amplitude für sein. Methoden, die in Produktzuständen kodieren, liefern im Allgemeinen flachere Circuits und können 1 oder 2 Merkmale pro Qubit speichern. Methoden, die Verschränkung nutzen und ein Merkmal mit einem Zustand statt mit einem Qubit verknüpfen, erzeugen tiefere Circuits und können im Durchschnitt mehr Merkmale pro Qubit speichern.
Doch Kodierung muss weder ausschließlich in Produktzuständen noch ausschließlich in verschränkten Zuständen wie bei der Amplitudenkodierung erfolgen. Tatsächlich erlauben viele in Qiskit integrierte Kodierungsschemas die Kodierung sowohl vor als auch nach einer Verschränkungsschicht, und nicht nur am Anfang. Dies wird als „Data Reuploading" bezeichnet. Für verwandte Arbeiten siehe Referenzen [5] und [6].
In diesem Abschnitt werden wir einige der integrierten Kodierungsschemata verwenden und visualisieren. Alle Methoden in diesem Abschnitt kodieren Merkmale als Rotationen auf parametrisierten Gates auf Qubits, wobei . Zu beachten ist, dass die Maximierung der Datenladung für eine gegebene Anzahl von Qubits nicht das einzige Kriterium ist. In vielen Fällen kann die Circuit-Tiefe ein noch wichtigeres Kriterium sein als die Qubit-Anzahl.
Efficient SU2
Ein gängiges und nützliches Beispiel für Kodierung mit Verschränkung ist Qiskits efficient_su2-Circuit. Beeindruckerweise kann dieser Circuit beispielsweise 8 Merkmale auf nur 2 Qubits kodieren. Schauen wir uns das an und versuchen dann zu verstehen, wie das möglich ist.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Wenn wir unseren Zustand aufschreiben, verwenden wir die Qiskit-Konvention, bei der die niedrigstwertigen Qubits ganz rechts angeordnet sind, wie in oder Diese Zustände können sehr schnell sehr kompliziert werden, und dieses seltene Beispiel kann erklären, warum solche Zustände selten explizit ausgeschrieben werden.
Unser System startet im Zustand Bis zur ersten Barriere (einem Punkt, den wir mit bezeichnen) sind unsere Zustände:
Das ist einfach dichtes Kodieren, das wir bereits kennen. Nach dem CNOT-Gate, an der zweiten Barriere (), ist unser Zustand:
Nun wenden wir den letzten Satz von Einzelqubit-Rotationen an und fassen gleiche Zustände zusammen:
Das ist wahrscheinlich zu kompliziert, um es vollständig nachzuvollziehen. Tritt stattdessen einen Schritt zurück und überlege, wie viele Parameter wir in den Zustand geladen haben: acht. Wir haben dabei nur vier Rechenbasisszustände. Auf den ersten Blick mag es scheinen, als hätten wir mehr Parameter geladen, als sinnvoll ist, da der Endzustand als geschrieben werden kann. Beachte jedoch, dass jeder Vorfaktor komplex ist! Wenn man es so schreibt:
sieht man, dass wir tatsächlich acht Parameter im Zustand haben, auf denen wir unsere acht Merkmale kodieren können.
Durch Erhöhung der Qubit-Anzahl und Erhöhung der Anzahl der Wiederholungen von Verschränkungs- und Rotationsschichten kann man deutlich mehr Daten kodieren. Das Aufschreiben der Wellenfunktionen wird schnell unlösbar. Aber wir können die Kodierung immer noch in Aktion sehen.
Hier kodieren wir den Datenvektor mit 12 Merkmalen auf einem 3-Qubit-efficient_su2-Circuit, wobei jedes der parametrisierten Gates ein anderes Merkmal kodiert.
In diesem Datenvektor sind die Merkmale in einer bestimmten Reihenfolge angegeben. Isoliert betrachtet spielt es keine Rolle, ob sie in dieser oder in umgekehrter Reihenfolge kodiert werden. Wichtig ist, die Reihenfolge zu verfolgen und konsistent zu bleiben. Beachte im Circuit-Diagramm, dass efficient_su2 eine bestimmte Kodierungsreihenfolge voraussetzt: Die erste Schicht parametrisierter Gates wird von Qubit 0 bis Qubit 2 befüllt, bevor zur nächsten Schicht übergegangen wird. Dies ist weder konsistent noch inkonsistent mit der Little-Endian-Notation, da die Datenmerkmale nicht a priori, also vor der Festlegung eines Kodierungs-Circuits, nach Qubit geordnet werden können.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Anstatt die Anzahl der Qubits zu erhöhen, könnte man auch die Anzahl der Wiederholungen von Verschränkungs- und Rotationsschichten erhöhen. Doch gibt es Grenzen, wie viele Wiederholungen sinnvoll sind. Wie bereits erwähnt, gibt es einen Kompromiss: Circuits mit mehr Qubits oder mehr Wiederholungen von Verschränkungs- und Rotationsschichten können mehr Parameter speichern, tun dies aber mit größerer Circuit-Tiefe. Wir werden weiter unten auf die Tiefen einiger integrierter Feature-Maps zurückkommen. Die nächsten Kodierungsmethoden, die in Qiskit integriert sind, haben „Feature Map" als Teil ihrer Namen. Halten wir noch einmal fest, dass das Kodieren von Daten in einen Quanten-Circuit eine Feature-Abbildung ist, in dem Sinne, dass sie Daten in einen neuen Raum überführt: den Hilbertraum der beteiligten Qubits. Die Beziehung zwischen der Dimensionalität des ursprünglichen Merkmalsraums und der des Hilbertraums hängt von dem für die Kodierung verwendeten Circuit ab.
-Feature-Map
Die -Feature-Map (ZFM) kann als natürliche Erweiterung der Phasenkodierung interpretiert werden. Die ZFM besteht aus abwechselnden Schichten von Einzelqubit-Gates: Hadamard-Gate-Schichten und Phasengatter-Schichten. Sei der Datenvektor mit Merkmalen gegeben. Der Quanten-Circuit, der die Feature-Abbildung durchführt, wird als unitärer Operator dargestellt, der auf den Anfangszustand wirkt:
wobei der -Qubit-Grundzustand ist. Diese Notation wird zur Konsistenz mit Referenz [4] (Havlicek et al.) verwendet. Die Datenmerkmale werden eins zu eins auf entsprechende Qubits abgebildet. Hat man beispielsweise 8 Merkmale in einem Datenvektor, verwendet man 8 Qubits. Der ZFM-Circuit besteht aus Wiederholungen eines Teilcircuits aus Hadamard-Gate-Schichten und Phasengatter-Schichten. Eine Hadamard-Schicht besteht aus einem Hadamard-Gate, das auf jedes Qubit in einem -Qubit-Register wirkt: , innerhalb derselben Algorithmusphase. Entsprechendes gilt für eine Phasengatter-Schicht, bei der das Qubit von beeinflusst wird. Jedes -Gate hat ein Merkmal als Argument, die Phasengatter-Schicht () ist jedoch eine Funktion des Datenvektors. Der vollständige ZFM-Circuit-Unitär mit einer einzelnen Wiederholung ist:
Wiederholungen dieses Unitärs ergeben dann:
Die Datenmerkmale werden in allen Wiederholungen auf die gleiche Weise auf die Phasengatter abgebildet. Der ZFM-Feature-Map-Zustand ist ein Produktzustand und für die klassische Simulation effizient[4].
Als kleines einführendes Beispiel wird ein Zwei-Qubit-ZFM-Circuit mit Qiskit kodiert und gezeichnet, um die einfache Circuit-Struktur zu zeigen. Im Beispiel wird eine einzelne Wiederholung, , mit dem Datenvektor implementiert. Beachte, dass dies in der Standardreihenfolge eines Vektors in Python geschrieben ist, d. h. das -te Element ist Wir können dieses -te Merkmal auf unser -tes Qubit oder auf unser -tes kodieren. Es kann nicht immer eine einzelne 1:1-Abbildung von der Merkmalsreihenfolge auf die Qubit-Reihenfolge geben, da verschiedene Feature-Maps unterschiedlich viele Merkmale pro Qubit kodieren. Entscheidend ist wieder, dass wir wissen, wo jedes Merkmal kodiert wird. Wenn man der -Feature-Map eine Parameterliste übergibt, kodiert sie Merkmal 0 aus der Liste auf das niedrigswertige Qubit mit einem parametrisierten Gate, also Qubit 0. Wir folgen dieser Konvention beim manuellen Vorgehen. Wir kodieren auf dem -ten Qubit und auf dem -ten Qubit.
Der ZFM-Circuit-Unitäroperator wirkt folgendermaßen auf den Anfangszustand:
Die Formel wurde um das Tensorprodukt herum umgestellt, um die Operationen auf jedem Qubit zu verdeutlichen. Der folgende Qiskit-Code verwendet Hadamard- und Phasengatter explizit, um die Struktur der ZFM zu zeigen:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Wir kodieren nun denselben Datenvektor in einen ZFM-Circuit mit drei Wiederholungen, , unter Verwendung der Qiskit-Klasse z_feature_map, was uns insgesamt die Quanten-Feature-Map liefert. Standardmäßig werden in der Klasse z_feature_map die Parameter mit 2 multipliziert, bevor sie auf das Phasengatter abgebildet werden. Um dieselben Kodierungen wie oben zu reproduzieren, dividieren wir durch 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Dies ist offensichtlich eine andere Abbildung als die oben manuell durchgeführte, aber beachte die Konsistenz in der Parameterreihenfolge: wurde erneut auf dem -ten Qubit kodiert.
Du kannst die ZFM über Qiskits ZFM-Klasse verwenden; du kannst diese Struktur auch als Inspiration nutzen, um deine eigene Feature-Abbildung zu konstruieren.
-Feature-Map
Die -Feature-Map (ZZFM) erweitert die ZFM durch die Einbeziehung von Zwei-Qubit-Verschränkungsgattern, insbesondere des -Rotationsgates . Es wird vermutet, dass die ZZFM im Allgemeinen auf einem klassischen Computer aufwendig zu berechnen ist, im Gegensatz zur ZFM.
implementiert eine -Wechselwirkung und ist für maximal verschränkend. kann in eine Folge von Gates auf zwei Qubits zerlegt werden, wie der folgende Qiskit-Code unter Verwendung des RZZ-Gates und der QuantumCircuit-Klassenmethode decompose zeigt. Wir kodieren ein einzelnes Merkmal des Datenvektors :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Wie oft üblich, sehen wir dies als einzelne gatterartige Einheit dargestellt, bis wir .decompose() verwenden, um alle einzelnen Gates zu sehen.
qc.decompose().draw("mpl", scale=1)

Daten werden mit einer Phasenrotation auf dem zweiten Qubit abgebildet. Das -Gate verschränkt die beiden Qubits, auf die es wirkt, in einem Ausmaß, das durch den kodierten Merkmalswert bestimmt wird.
Der vollständige ZZFM-Circuit besteht aus einem Hadamard-Gate und einem Phasengatter, wie in der ZFM, gefolgt von der oben beschriebenen Verschränkung. Eine einzelne Wiederholung des ZZFM-Circuits ist:
wobei eine ZZ-Gate-Schicht enthält, die durch ein Verschränkungsschema strukturiert ist. Mehrere Verschränkungsschemata werden in den folgenden Codeblöcken gezeigt. Die Struktur von enthält auch eine Funktion, die die Datenmerkmale der zu verschränkenden Qubits auf folgende Weise kombiniert. Angenommen, das -Gate soll auf die Qubits und angewendet werden. In der Phasenschicht haben diese Qubits Phasengatter, die bzw. kodieren. Das Argument von ist nicht einfach eines dieser Merkmale, sondern eine Funktion, die häufig mit bezeichnet wird (nicht zu verwechseln mit dem Azimutwinkel):
Wir werden dies in mehreren Beispielen weiter unten sehen. Die Erweiterung auf mehrere Wiederholungen ist dieselbe wie im Fall der z_feature_map:
Da die Operatoren komplexer geworden sind, kodieren wir zunächst einen Datenvektor mit einer Zwei-Qubit-ZZFM und einer Wiederholung mithilfe des folgenden Codes:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Standardmäßig werden in Qiskit die Merkmale gemeinsam auf durch diese Abbildungsfunktion abgebildet. Qiskit erlaubt es dem Nutzer, die Funktion (oder , wobei die Menge der Qubit-Paare ist, die durch -Gates gekoppelt sind) als Vorverarbeitungsschritt anzupassen.
Mit einem vierdimensionalen Datenvektor und der Abbildung auf eine Vier-Qubit-ZZFM mit einer Wiederholung lässt sich die Abbildung für verschiedene Qubit-Paare erkennen. Wir können auch die Bedeutung von „linearer" Verschränkung erkennen:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

Im linearen Verschränkungsschema werden nächste-Nachbarn-Paare (nummerierte) von Qubits in diesem Circuit verschränkt. Es gibt weitere integrierte Verschränkungsschemata in Qiskit, darunter circular und full.
Pauli-Feature-Map
Die Pauli-Feature-Map (PFM) ist die Verallgemeinerung der ZFM und ZZFM auf beliebige Pauli-Gates. Die Pauli-Feature-Map hat eine sehr ähnliche Form wie die beiden vorherigen Feature-Maps. Für Wiederholungen der Kodierung der Features des Vektors gilt:
Bei der PFM wird zu einem verallgemeinerten unitären Pauli-Entwicklungsoperator. Hier stellen wir eine allgemeinere Form der bisher betrachteten Feature-Maps vor:
wobei ein Pauli-Operator ist, . Hierbei ist die Menge aller Qubit-Konnektivitäten, wie sie durch die Feature-Map bestimmt werden, einschließlich der Menge der Qubits, auf die Einzelqubit-Gates wirken. Das heißt, für eine Feature-Map, bei der auf Qubit 0 ein Phase-Gate und auf die Qubits 2 und 3 ein -Gate angewendet wird, enthält die Menge die Elemente . durchläuft alle Elemente dieser Menge. In den vorherigen Feature-Maps war die Funktion entweder ausschließlich mit Einzelqubit-Gates oder ausschließlich mit Zweiqubit-Gates verknüpft. Hier definieren wir sie allgemein:
Die Dokumentation findest du in der Qiskit-Dokumentation zur Pauli feature map-Klasse). In der ZZFM ist der Operator auf beschränkt.
Eine Möglichkeit, den obigen unitären Operator zu verstehen, ist die Analogie zum Propagator in einem physikalischen System. Der obige unitäre Operator ist ein unitärer Zeitentwicklungsoperator, , für einen Hamiltonian , ähnlich dem Ising-Modell, wobei der Zeitparameter durch Datenwerte ersetzt wird, um die Entwicklung anzutreiben. Die Entwicklung dieses unitären Operators ergibt den PFM-Circuit. Die Verschränkungskonnektivitäten in können als Ising-Kopplungen in einem Spin-Gitter interpretiert werden.
Betrachten wir ein Beispiel mit Pauli-- und -Operatoren, die diese Ising-artigen Wechselwirkungen repräsentieren. Qiskit stellt eine pauli_feature_map-Klasse zur Verfügung, mit der eine PFM mit einer Auswahl von Einzel- und -Qubit-Gates instanziiert werden kann. In diesem Beispiel werden diese als Pauli-Strings 'Y' und 'XX' übergeben. Typischerweise ist 1 oder 2 für Einzel- bzw. Zweiqubit-Wechselwirkungen. Das Verschränkungsschema ist „linear", das heißt, es werden nur nächste-Nachbar-Qubits im Quantum Circuit gekoppelt. Beachte, dass dies nicht den nächsten Nachbar-Qubits auf dem eigentlichen Quantencomputer entspricht, da dieser Quantum Circuit eine Abstraktionsschicht darstellt.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit stellt in Pauli-Feature-Maps einen Parameter zur Verfügung, mit dem die Skalierung der Pauli-Rotationen gesteuert werden kann.
Der Standardwert von ist . Durch Optimierung seines Wertes im Intervall, zum Beispiel lässt sich ein Quanten-Kernel besser an die Daten anpassen.
Galerie der Pauli-Feature-Maps
Hier visualisieren wir verschiedene Pauli-Feature-Maps für Zweiqubit-Circuits, um einen besseren Überblick über die Bandbreite der Möglichkeiten zu erhalten.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Das obige Beispiel lässt sich natürlich um weitere Permutationen und Wiederholungen von Pauli-Matrizen erweitern. Lernende sind eingeladen, mit diesen Optionen zu experimentieren.
Überblick über die integrierten Feature-Maps
Du hast verschiedene Verfahren zur Kodierung von Daten in einen Quantum Circuit kennengelernt:
- Basis-Kodierung
- Amplitudenkodierung
- Winkelkodierung
- Phasenkodierung
- Dichte Kodierung
Du hast gesehen, wie du eigene Feature-Maps mit diesen Kodierungsverfahren aufbaust, und du hast vier integrierte Feature-Maps kennengelernt, die Winkel- und Phasenkodierung nutzen:
- Efficient SU2
- Z-Feature-Map
- ZZ-Feature-Map
- Pauli-Feature-Map
Diese integrierten Feature-Maps unterscheiden sich in mehreren Punkten voneinander:
- Die Tiefe bei einer gegebenen Anzahl kodierter Features
- Die Anzahl der Qubits, die für eine bestimmte Anzahl von Features benötigt werden
- Der Grad der Verschränkung (was offensichtlich mit den anderen Unterschieden zusammenhängt)
Der folgende Code wendet diese vier integrierten Feature-Maps auf die Kodierung eines Feature-Sets an und stellt die Zweiqubit-Tiefe des resultierenden Circuits dar. Da die Fehlerrate bei Zweiqubit-Gates deutlich höher ist als bei Einqubit-Gates, ist die Tiefe der Zweiqubit-Gates besonders interessant. Im folgenden Code ermitteln wir die Anzahl aller Gates in einem Circuit, indem wir den Circuit zunächst dekompilieren und dann count_ops() verwenden, wie unten gezeigt. Die Zweiqubit-Gates, die uns hier interessieren, sind 'cx'-Gates:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Im Allgemeinen führen Pauli- und ZZ-Feature-Maps zu einer größeren Circuit-Tiefe und einer höheren Anzahl an 2-Qubit-Gates als efficient_su2 und Z-Feature-Maps.
Da die in Qiskit integrierten Feature-Maps sehr vielseitig einsetzbar sind, muss man in der Lernphase meist keine eigenen entwerfen. Experten für Quanten-Maschinelles-Lernen werden jedoch wahrscheinlich auf das Thema des Entwerfens eigener Feature-Mappings zurückkommen, wenn sie sich mit zwei komplexen Herausforderungen befassen:
-
Moderne Hardware: Das Vorhandensein von Rauschen und der hohe Overhead von fehlerkorrigierendem Code bedeuten, dass aktuelle Anwendungen Aspekte wie Hardware-Effizienz und die Minimierung der Zweiqubit-Gate-Tiefe berücksichtigen müssen.
-
Mappings, die zum jeweiligen Problem passen: Es ist eine Sache zu sagen, dass die
zz_feature_mapzum Beispiel klassisch schwer zu simulieren und daher interessant ist. Eine ganz andere Sache ist es, ob diezz_feature_mapideal für deine Machine-Learning-Aufgabe oder deinen Datensatz geeignet ist. Die Performance verschiedener parametrisierter Quanten-Circuits auf verschiedenen Datentypen ist ein aktives Forschungsgebiet.
Wir schließen mit einem Hinweis zur Hardware-Effizienz.
Hardware-effizientes Feature-Mapping
Ein hardware-effizientes Feature-Mapping berücksichtigt die Einschränkungen realer Quantencomputer mit dem Ziel, Rauschen und Fehler bei der Berechnung zu reduzieren. Beim Ausführen von Quantum Circuits auf Quantencomputern der nahen Zukunft gibt es viele Strategien zur Minderung des der Hardware innewohnenden Rauschens. Eine wichtige Strategie für Hardware-Effizienz ist die Minimierung der Tiefe des Quantum Circuits, damit Rauschen und Dekohärenz weniger Zeit haben, die Berechnung zu korrumpieren. Die Tiefe eines Quantum Circuits ist die Anzahl der zeitlich ausgerichteten Gate-Schritte, die zur Durchführung der gesamten Berechnung erforderlich sind (nach Circuit-Optimierung)[5]. Beachte, dass die Tiefe des abstrakten, logischen Circuits möglicherweise viel geringer ist als die Tiefe nach dem Transpilieren für einen echten Quantencomputer.
Transpilation ist der Prozess der Umwandlung des Quantum Circuits von einer abstrakten Darstellung auf hoher Ebene in eine Form, die auf einem echten Quantencomputer ausgeführt werden kann, wobei die Hardware-Einschränkungen berücksichtigt werden. Ein Quantencomputer verfügt über einen nativen Satz von Einzel- und Zweiqubit-Gates. Das bedeutet, dass alle Gates im Qiskit-Code in den Satz nativer Hardware-Gates transpiliert werden müssen. In ibm_torino zum Beispiel, einem QPU mit einem Heron-r1-Prozessor, der 2023 fertiggestellt wurde, sind die nativen bzw. Basis-Gates {CZ, ID, RZ, SX, X}. Dies sind das Zweiqubit-Controlled-Z-Gate und Einqubit-Gates namens Identity, -Rotation, Quadratwurzel von NOT und NOT, die zusammen einen universellen Satz bilden. Bei der Implementierung von Mehrqubit-Gates als äquivalente Teilschaltung werden physikalische Zweiqubit--Gates zusammen mit anderen in der Hardware verfügbaren Einqubit-Gates benötigt. Um ein Zweiqubit-Gate auf einem Qubitpaar anzuwenden, das nicht physisch gekoppelt ist, werden zudem SWAP-Gates hinzugefügt, um Qubit-Zustände zwischen Qubits zu verschieben und so die Kopplung zu ermöglichen – was zu einer unvermeidlichen Verlängerung des Circuits führt. Mit dem Argument optimization, das von 0 bis zu einem Höchstwert von 3 eingestellt werden kann, lässt sich die Optimierung steuern. Für mehr Kontrolle und Anpassbarkeit kann die Transpiler-Pipeline mit dem Qiskit Pass Manager verwaltet werden. Weitere Informationen zur Transpilation findest du in der Qiskit-Transpiler-Dokumentation.
In Havlicek et al. 2019 [2] erreichen die Autoren Hardware-Effizienz unter anderem dadurch, dass sie die -Feature-Map verwenden, da es sich um eine Entwicklung zweiter Ordnung handelt (siehe den Abschnitt „-Feature-Map" oben). Eine Entwicklung -ter Ordnung hat -Qubit-Gates. IBM®-Quantencomputer haben keine nativen -Qubit-Gates für ; deren Implementierung würde daher eine Zerlegung in Zweiqubit-CNOT-Gates erfordern, die in der Hardware verfügbar sind. Eine zweite Möglichkeit, mit der die Autoren die Tiefe minimieren, besteht darin, eine -Kopplungstopologie zu wählen, die direkt auf die Architektur-Kopplungen abgebildet wird. Eine weitere Optimierung, die sie vornehmen, ist die Auswahl einer leistungsstärkeren, geeignet verbundenen Hardware-Teilschaltung. Weitere zu berücksichtigende Aspekte sind die Minimierung der Anzahl der Feature-Map-Wiederholungen und die Wahl eines maßgeschneiderten, tiefenoptimierten oder „linearen" Verschränkungsschemas anstelle des „vollen" Schemas, das alle Qubits verschränkt.

Die obige Grafik zeigt ein Netzwerk von Knoten und Kanten, die physische Qubits bzw. Hardware-Kopplungen repräsentieren. Die Kopplungskarte und die Performance von ibm_torino sind mit allen möglichen Zweiqubit-CZ-Kopplungs-Gates dargestellt. Die Qubits sind farbkodiert auf einer Skala basierend auf der T1-Relaxationszeit in Mikrosekunden (μs), wobei längere T1-Zeiten besser sind und in einem helleren Farbton dargestellt werden. Die Kopplungskanten sind nach dem CZ-Fehler farbkodiert, wobei dunklere Farbtöne besser sind. Informationen zur Hardware-Spezifikation sind im Hardware-Backend-Konfigurationsschema IBMQBackend.configuration() abrufbar.
Referenzen
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()